What is a CID?
When we exchange data with peers on the decentralized web, we depend on content addressing (as opposed to the location addressing of the centralized web) to securely locate and identify data. If you haven't yet done so, please check out our Content Adddressing on the Decentralized Web tutorial to learn about the basics of important decentralized web concepts like content addressing, cryptographic hashing, content identifiers (CIDs), and sharing with peers. In this tutorial we'll dig deep into the anatomy of CIDs, which are constructed from a variety of self-describing values defined by the Multiformats project.
The CID specification, which originated in IPFS, now lives in Multiformats and supports a broad range of projects including IPFS, IPLD, libp2p, and Filecoin. Although we'll share some IPFS examples throughout our lessons, this tutorial is about the anatomy of the CID itself, which is used by each of these distributed information systems as the core identifier to reference content.
A content identifier, or CID, is a self-describing content-addressed identifier. It doesn't indicate where content is stored, but it forms a kind of address based on the content itself. The number of characters in a CID depends on the cryptographic hash of the underlying content, rather than the size of the content itself. As most content in IPFS is hashed using sha2-256, most CIDs you encounter there will be the same size (256 bits, which equates to 32 bytes). This makes them much easier to manage, especially when dealing with multiple pieces of content.
For example, if we stored an image of an aardvark on the IPFS network, its CID would look like this: QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
The first step to creating a CID is to transform the input data, using a cryptographic algorithm that maps input of arbitrary size (data or a file) to output of a fixed size. This transformation is known as cryptographic hash digest or simply hash.
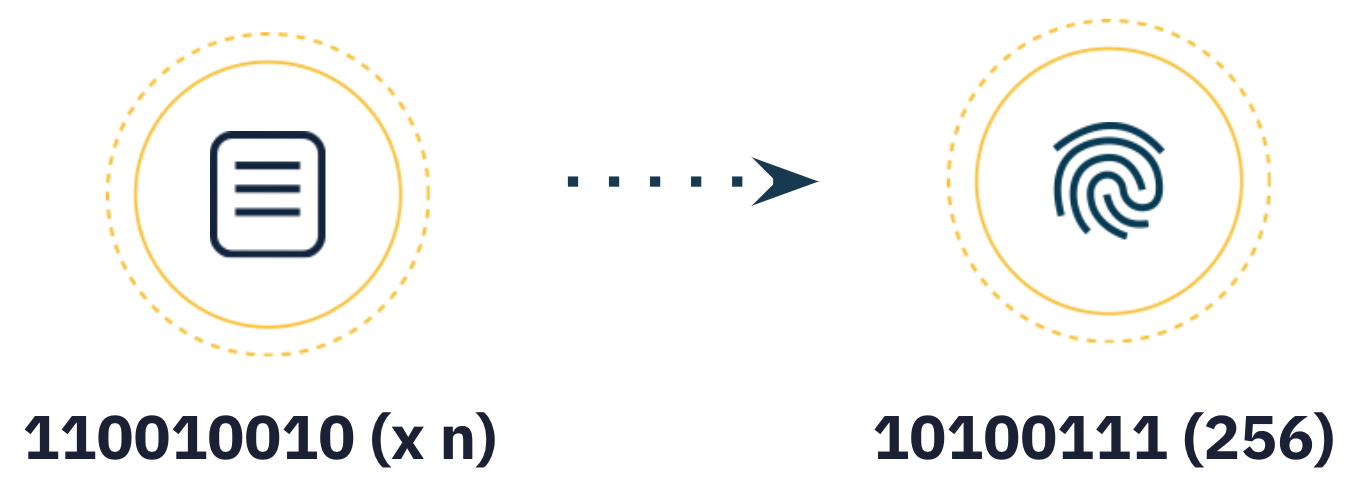
The cryptographic algorithm used must generate hashes that have the following characteristics:
- Deterministic: The same input should always produce the same hash.
- Uncorrelated: A small change in the input should generate a completely different hash.
- One-way: It should be infeasible to reconstruct the data from the hash.
- Unique: Only one file can produce one specific hash.
Note that if we change a single pixel in our aardvark image, our cryptographic algorithm will generate a completely different hash for the image. When we fetch data using a content address, we're guaranteed to see the intended version of that data. This is quite different from location addressing on the centralized web, where the content at a given address (URL) can change over time.
Cryptographic hashing is not unique to IPFS, and there are many hashing algorithms out there like sha2-256, blake2b, sha3-256 and sha3-512, the no-longer-secure sha1 and md5, etc. IPFS uses sha2-256 by default, though a CID supports virtually any strong cryptographic hash algorithm.
Take the quiz!
What is the default cryptographic algorithm used by IPFS to generate CIDs?
Feeling stuck? We'd love to hear what's confusing so we can improve this lesson. Please share your questions and feedback.