One hash, multiple CID versions
You can paste any IPFS CID into the handy CID Inspector to visualize all of its prefixes and what they represent.
In this final lesson we will take a look at some results from this tool using both CIDv0 and CIDv1 formats.
Example 1: CIDv1
bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi
This first example is a version 1 CID.
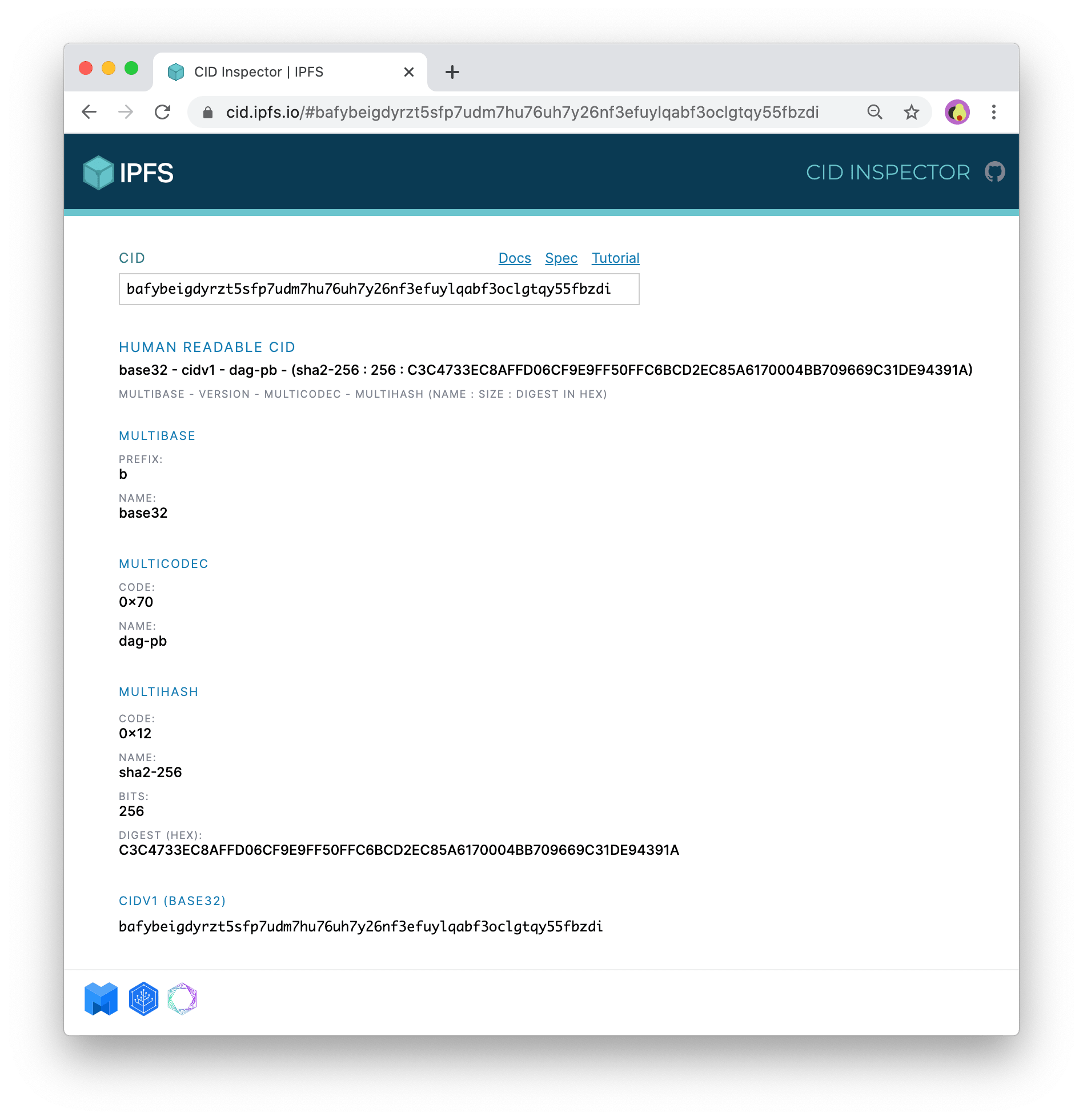
Looking at the results from the CID Inspector tool we can see several parts that the tool was able to parse for us:
Human Readable CID: breaks down each part of the CID to be easily readable by us humansMultibase:codeis the identifier of the base, in this casebforbase32.Multicodec:codeis the identifier of the codec, in this case0x70fordag-pb, an IPLD formatMultihash: breakdown of the multihash into the hashing algorithm used (18is the code forsha2-256), the length of the hash (256 bits, which equates to 32 bytes), and the content hash itself (digest hex).
From the "Human Readable CID" breakdown, we can see that the original hash of the content, before the appropriate CIDv1 prefixes are added, is C3C4733EC8AFFD06CF9E9FF50FFC6BCD2EC85A6170004BB709669C31DE94391A.
Example 2: CIDv0
QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR
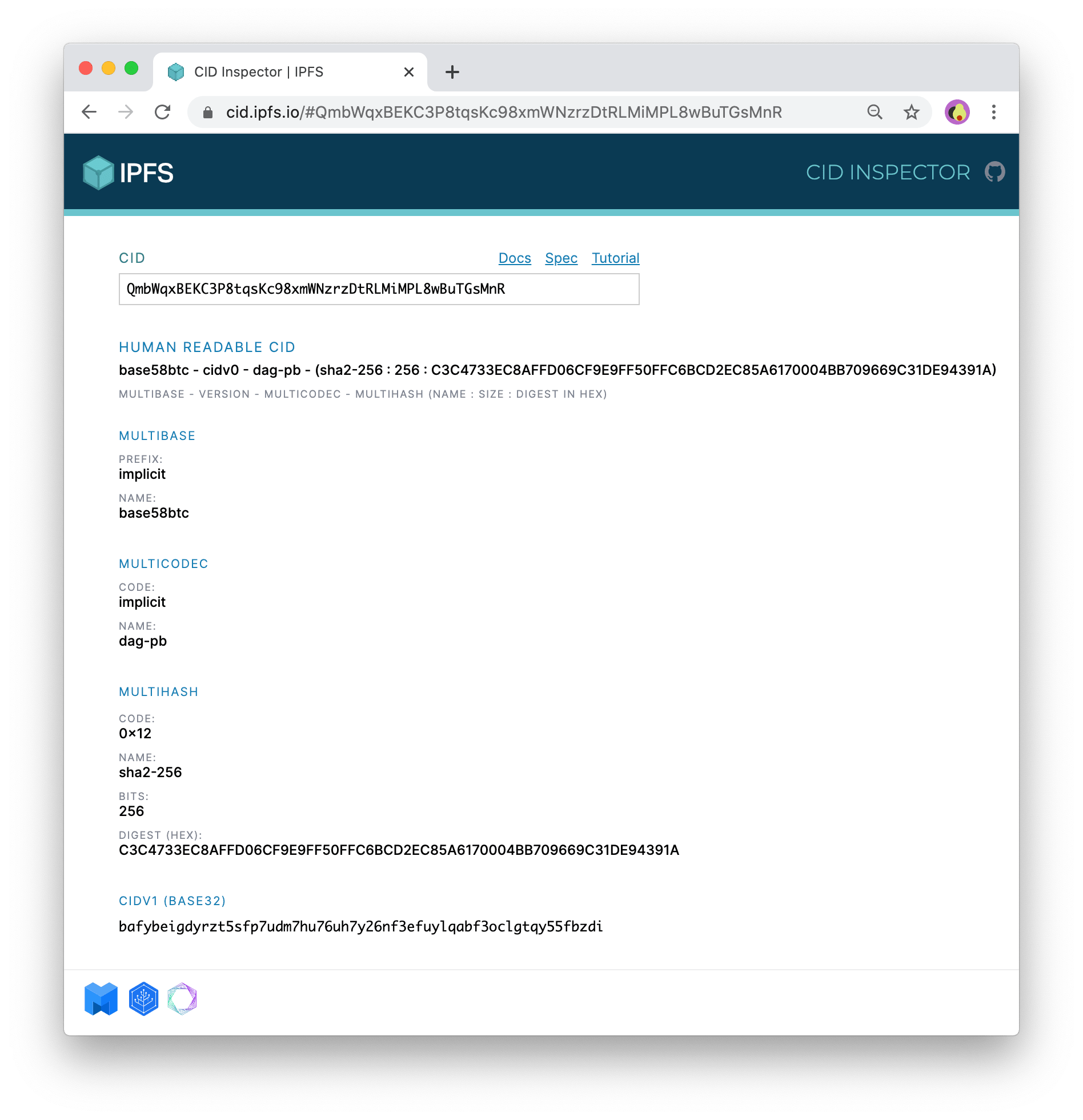
This Version 0 CID shows some different results: both the multibase and the multicodec are listed as "implicit".
Since Version 0 CIDs did not have those prefixes, they are always assumed to be base58btc and dag-pb respectively.
Under the Base32 CIDV1 label we see bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi, which is the same CID from the first example! The CID Inspector has offered us a conversion from CIDv0 to CIDv1.
Notice also how the end of the "Human Readable CID" (the portion after the prefixes) is exactly the same in this CIDv0 example as it was in the CIDv1 example: C3C4733EC8AFFD06CF9E9FF50FFC6BCD2EC85A6170004BB709669C31DE94391A.
Why? These two CIDs point to the same content. Basically, it's the same hash (C3C4733EC8AFFD06CF9E9FF50FFC6BCD2EC85A6170004BB709669C31DE94391A) represented in the two different versions of the CID spec.
Converting CID versions
You can convert any CIDv0 to CIDv1, because the implicit prefixes from v0 become explicit in v1.
However, because CIDv1 supports multiple codecs and multiple bases and CIDv0 does not, not all CIDv1 can be converted to CIDv0. In fact, only CIDv1 that have the following properties can be converted to CIDv0:
multibase = base58btcmulticodec = dag-pbmultihash-algorithm = sha2-256multihash-length = 32(32 bytes, equivalent to 256 bits)
To test this theory, you can check out our beloved aardvark image here, hosted on the IPFS network: https://ipfs.io/ipfs/QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
- Open the link in your browser and copy the CID from the end of the URL (
QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF) - In a new browser window, paste it into the CID Inspector tool and find the equivalent CIDv1 value displayed at the bottom of the screen
- Back in your aardvark tab, replace the
v0CID with the convertedv1CID in the original URL and refresh the page
You should see the same image of our aardvark.
Take the quiz!
If we have two different CIDs pointing to the same content, doesn't that break the 'uniqueness' rule specified in the first lesson?
Feeling stuck? We'd love to hear what's confusing so we can improve this lesson. Please share your questions and feedback.